Results & Findings
Manual review of the 10,000-image test set identified approximately 8–10 images as genuinely sensitive — a rate of roughly 1% of the corpus. This low base rate is important context for interpreting both classification performance and false positive rates: at 1% prevalence, even a highly accurate model will produce more false positives than true positives in absolute terms.
The semantic method's 16.5% precision on flagged items reflects both the challenge of this low-prevalence setting and the inherent ambiguity of archival content. The 73.4% "borderline" rate suggests that the sensitivity threshold is approximately correct, but that human expert judgment remains essential for a meaningful portion of flagged images.
The most reliable detected categories were Human Remains (skull, skeleton keywords) and Violence/Graphic Content (explosion, fire keywords) — categories where visual descriptions map cleanly to unambiguous taxonomy terms. Categories like Native American Imagery and Historical Racialized Performance proved harder to classify reliably, as descriptions often lacked explicit cultural context cues.
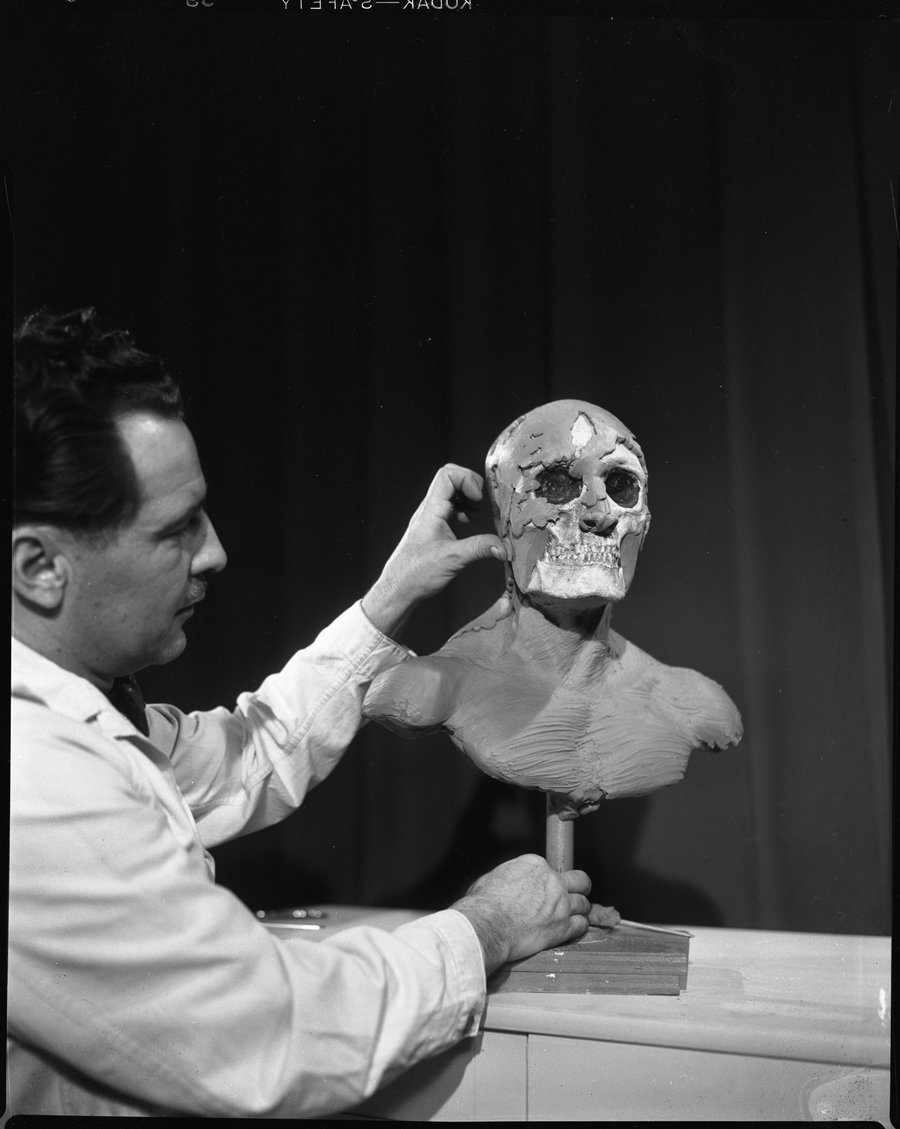
Strict description: "A man is holding up a skull to the face of a dummy head for display purposes."
Matched keyword: skull → Category: Human Remains. Clean, unambiguous match.

LLaVA description: "Two women wearing medieval outfits stand side by side with a man."
The photograph actually shows one man and one woman in period theatrical costume — a separate model perception error worth noting. Flagged as Native American imagery due to semantic overlap between "ceremonial" and "medieval costume." Both the count error and the false-positive category illustrate the challenge of using general-purpose multimodal descriptions as inputs to a moderation classifier.